Selected Projects
Automatic pricing competition. An experiment with simulated Amazon seller.
Made in Python with Django
This study investigates how platform-provided automation tools affect long-term pricing equilibria in online marketplaces (such as Amazon). In an online simulation, participants act as sellers, each managing two marketplaces simultaneously: one with access to automated pricing tools and one without. In each marketplace, every seller competes with two other sellers. The project required the development of a special software for asynchronous client connections, allowing for several hundred simultaneous connections on a single node with real-time market simulations.
Economics keywords: market equilibrium, pricing automation, experimental economics
Computer Science keywords: Cloud Services, AWS EC2, Django, linux KVM, Asynchronous communications
2022
Product Launches with New Attributes: A Hybrid Conjoint-Consumer Panel Technique for Estimating Demand. Neural network estimation.
Made in Python, R, Keras
Conjoint analysis is a powerful tool for predicting individual preferences for new-to-market product attributes. However, it relies on stated preferences, which are prone to biases. In contrast, revealed preference demand estimation, derived from actual consumer purchase data, offers greater accuracy for existing products but cannot assess new-to-market attributes. This paper introduces a hybrid demand estimation method integrating data from conjoint surveys and consumer panel purchases. Using structurally built neural networks (NN+S approach), regularized and tuned for optimal out-of-sample prediction, this method bridges the gap between stated and revealed preferences, providing a robust solution for predicting demand across existing and novel product attributes.
Economics keywords: Hierarchical Linear Models, Individual demand estimation, Hybrid Estimations, Data fusion
Computer Science keywords: Custom Neural Networks, Cross-validation
2021
Improving the substitution patterns of aggregate demand models
Made in Julia, Python, R
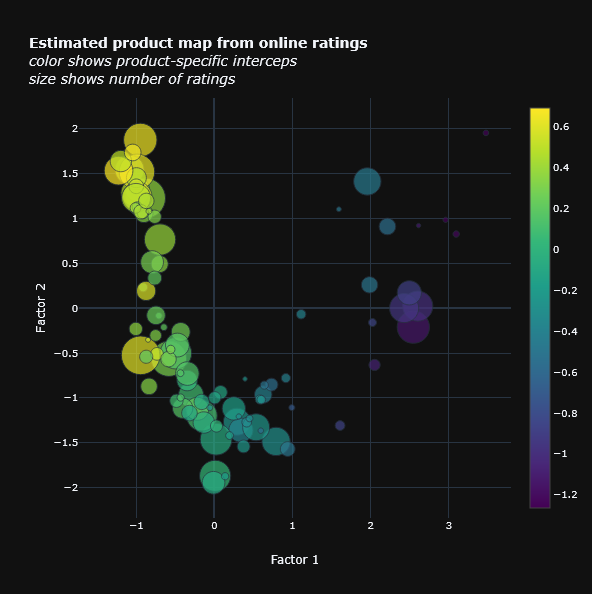
Modern aggregate demand models with random coefficients use observed product characteristics to capture product substitution patterns. This project explores a matrix factorization approach to estimate unobserved product characteristics from online ratings in the beer industry. These estimated characteristics offer key advantages over observed ones, including greater relevance, improved interpretability, and lower dimensionality. This method can also be applied to estimate unobserved characteristics in industries such as video games, movies, and books, enhancing the accuracy of substitution pattern estimates between products.
The main internal loop is implemented with Julia, which makes the algorithm lightning fast (zero memory allocation).
Overcame the problem of numerical stability, which researchers commonly report.
Custom-made gradient-based optimization algorithm.
Economics keywords: cross-price elasticity, GMM, bootstrapping, BLP modeling
Data Science keywords: data cleaning, PCA, SVD, hyper-parameters tuning, regularization, cross-validation, cluster computing, shell scripting
2020
Matrix factorization using neural networks
Made in Python
Matrix factorization techniques, such as Singular Value Decomposition (SVD), are widely used in recommender systems. This project aims to implement SVD using a neural network to enhance convergence to the global minimum. By representing mathematical models as custom neural networks, we can leverage standard deep learning frameworks like Keras, TensorFlow, and PyTorch for efficient training. Multiple robots perform fault-tolerant web scraping in parallel.
Economics keywords: product map, individual tastes heterogeneity, individual scale usage
Data Science keywords: web scraping, neural networks, SVD, hyper-parameters tuning, regularization, cross-validation
2019
Human-like web-scraping
Made in R
In some instances, web scraping cannot be performed using automated bots. To successfully gather the required data, your program must mimic human behavior. This involves taking time to process information, responding to on-screen events, and moving the mouse cursor in a human-like manner. With the RSelenium package and careful implementation, this level of automation is achievable.
Multiple robots perform fault-tolerant web scraping in parallel
A unique identity for each robot
An extra process that orchestrates all the robots to make a stratified sample
2019
Getting insights from text-mining of online reviews
Made in R
Text mining can be used to investigate product closeness. An underlying assumption is that products with similar user experiences will receive similar user reviews.
Data Science keywords: web scraping, neural networks, SVD, hyperparameter tuning, regularization, cross-validation
2019
Analysis of keywords search money spending
Made in R
There are plenty of online tools for analyzing keywords. None of them is better than the data from your own advertising campaigns. The idea was to combine the data from individual keywords advertising campaigns and the spatial locations of the competitors to increase the conversion rate per dollar spent.
2019
Quasi-experiment in online reviews
Made in R
Econometric study on the presence of social bias in online user reviews in the context of the video game industry. The study exploits the fact that some websites report average ratings for the games by aggregating for each platform separately (PC, Xbox, etc.), while other websites report average ratings for the games by pooling all the platforms together.
Economics keywords: diff-in-diff, quasi-natural experiment
2018
Continuous web-scraping
Made in C#, MySQL
Sometimes, you must visit a page multiple times to get a single observation. The project's goal is to develop a library for gathering such observations, which has been used in several other projects.
Fault-tolerant custom-made ORM
100'000 requests per day from a single node
2017
Software for semi-automatic parsing huge text of data
Made in Java
The idea was to quantify the information from a particular book. The book was scanned and recognized with many mistakes. The number of mistakes didn't allow for the development of a fully automatic parser. The solution was to develop a semi-automatic parser, which did all the heavy lifting automatically while asking an operator (human) to resolve the most fault-critical situations.
2013
LAN based games with stabilo-cheers synchronization
Made in C++ using RakNet, Irrlicht, .NET
The project aimed to develop software that allows conducting different experiments in the Laboratory of Experimental Economics at MIPT. The software was able to track the movement of individuals' center masses and mouse movements while individuals were playing Experimental Economics games over a LAN.
2011
Egor Kudriavtcev
Empowering businesses with data-driven solutions
Contact
Connect
© 2025. All rights reserved.